ResearchMatch
Finding the right professor to work with shouldn't feel like doom-scrolling through half-broken faculty pages and Google Scholar profiles.
ResearchMatch flips that script with an automated pipeline that scrapes, enriches & ranks research profiles, then serves lightning-fast matches through an elegant web UI.
Below is a behind-the-scenes look at the architecture you can run in a single Python script today—and the cloud-native design.
Why We Built It
Lower the barrier to undergraduate and graduate research.
Benchmark LLMs against traditional NLP baselines on a real task.
Exercise full-stack muscle—from scrapers to observability dashboards to attempt to solve its engineering at scale.
Current MVP Architecture
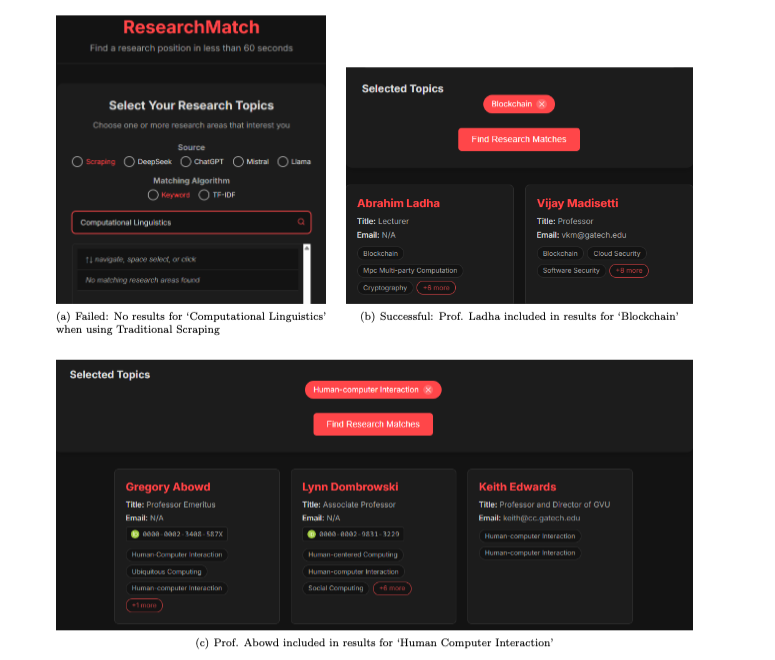
Traditional Scraping:
Crawl College-of-Computing (We did for Georgia tech, but it should work for other universities too) faculty pages → names, bios, personal sites, Scholar & ORCID links → BeautifulSoup, DuckDuckGo API
Four LLM Scrapers:
DeepSeek, GPT-4o, Mistral & Llama ingest each professor’s first Scholar page and produces a list of research topics
Matching Engine:
Keyword, TF-IDF & Word2Vec rank professors against the student’s query (secondary sort by citations/h-index)scikit-learn, gensim
Streamlit Dashboards:
Precision, recall, F1, BLEU, ROUGE plus live latency distributions.
Streamlit, Plotly— Redis Cache. Last 1000 queries cached as {query_hash → response_blob} to short-circuit recomputation.
Take-away: in <300 LOC we support five scraping methods, three matchers, evaluation against Perplexity SONAR “ground truth,” and a real-time metrics board—all backed by a single JSON file.
Performance Insights
LLM vs. Scraping: vanilla keyword scraping and Llama nudged out GPT-class models on F1 (≈ 0.27 vs 0.24) because Scholar bios contain well-tokenised keywords.
Caching matters: exact-keyword queries were already µs-level, but TF-IDF & Word2Vec dropped from ~5 ms to sub-ms when the Redis layer hit.
Latency dashboard: box-plots + rolling 90 % CIs gave us instant feedback when an LLM endpoint slowed down or cache-hit ratios slipped. (See plots below.)
The Road to Production-Scale
1 · Ingestion
Cloud-native upgrade: AWS Step Functions coordinate K8s scraper jobs on Fargate, publishing results to Kafka
Why it scales: serverless, auto-scaling workers with built-in retry semantics
2 · Enrichment
Cloud-native upgrade: Flink / Kinesis stream processor feeds stateless LLM micro-services that add embeddings & topic labels
Why it scales: parallel shard-out, lower per-message cost, easy horizontal expansion
3 · Storage
Cloud-native upgrade: Iceberg + S3 data lake, Aurora Postgres for metadata, Pinecone vector search
Why it scales: clean separation of hot vs. cold data, infinite object-store capacity, and managed vector indexing
4 · Core APIs
Cloud-native upgrade: Matching Engine (TF-IDF + ANN) and Personalisation service exposed via gRPC / GraphQL
Why it scales: low-latency, strongly-typed contracts, efficient binary transport
5 · Edge & UI
Cloud-native upgrade: CloudFront with global Redis edge cache, JWT/OIDC auth, Next.js SPA & Flutter mobile apps
Why it scales: < 100 ms P99 reads worldwide, authenticated and cached at the edge
- Observability
Cloud-native upgrade: Prometheus metrics, OpenTelemetry traces, CloudWatch logs
Why it scales: uniform telemetry → safe, zero-downtime rollouts and rapid incident triage
Caching in the Future Design
Edge cache (CloudFront + Global Redis) for fully rendered search pages.
Micro-cache inside the Matching Engine for 1 s hot-query bursts.
Vector-search cache in Pinecone’s pod memory—evicts on LRU by embedding norm.
LLM response cache (S3 + Athena) keyed by [model, prompt_hash] to amortise API spend.
What’s Next
Incremental scraping using change-feeds rather than full re-crawls.
Hybrid ranker that blends BM25, ANN & re-ranking LLM in a single gRPC hop.
Personalised digests—a Notification Hub surfaces new papers the moment they land.
ResearchMatch started as a 500 profiles JSON prototype; the envisioned pipeline can ingest every faculty profile on Earth and serve sub-second, personalised matches.
We built this as a team at Georgia Tech for CS6675: Advanced Internet Systems and Applications
- Shrey Gupta
Read on Substack